library(tidyverse) # for everything
library(NHANES) # for data
library(rstatix) # for pipe friendly statistics functions
library(ggpubr) # for easy annotating of stats
library(glue) # for easy pasting
library(rcompanion) # for creating the comparison table Adding Statistics Recitation Solutions
Week 9
Introduction
Today you will be practicing what we learned in today’s class on adding statistics to your plots.
Load data
We will be using the NHANES data again from the package NHANES.
Is total cholesterol (TotChol) different by age (AgeDecade)?
Need a hint? (Click to expand)
Hint - you want to test your assumptions to see what tests to do. You might need to use different posthoc comparison methods than we did in class.
Need another hint? (Click to expand)
Another hint - the function rcompanion::cldList() will convert the resulting comparison table from a posthoc Dunn test to create a column with the letters indicating which groups are significantly different from each other.
Base plot
Plot to get an overview.
(totchol_age_baseplot <- NHANES %>%
drop_na(AgeDecade, TotChol) %>%
ggplot(aes(x = AgeDecade, y = TotChol, group = AgeDecade)) +
geom_boxplot() +
theme_minimal() +
theme(legend.position = "none") +
labs(x = "Age, by Decade",
y = "Total Cholesterol (mmol/L)",
title = "Differences in total cholesterol by age in NHANES 2009/2010, and 2011/2012"))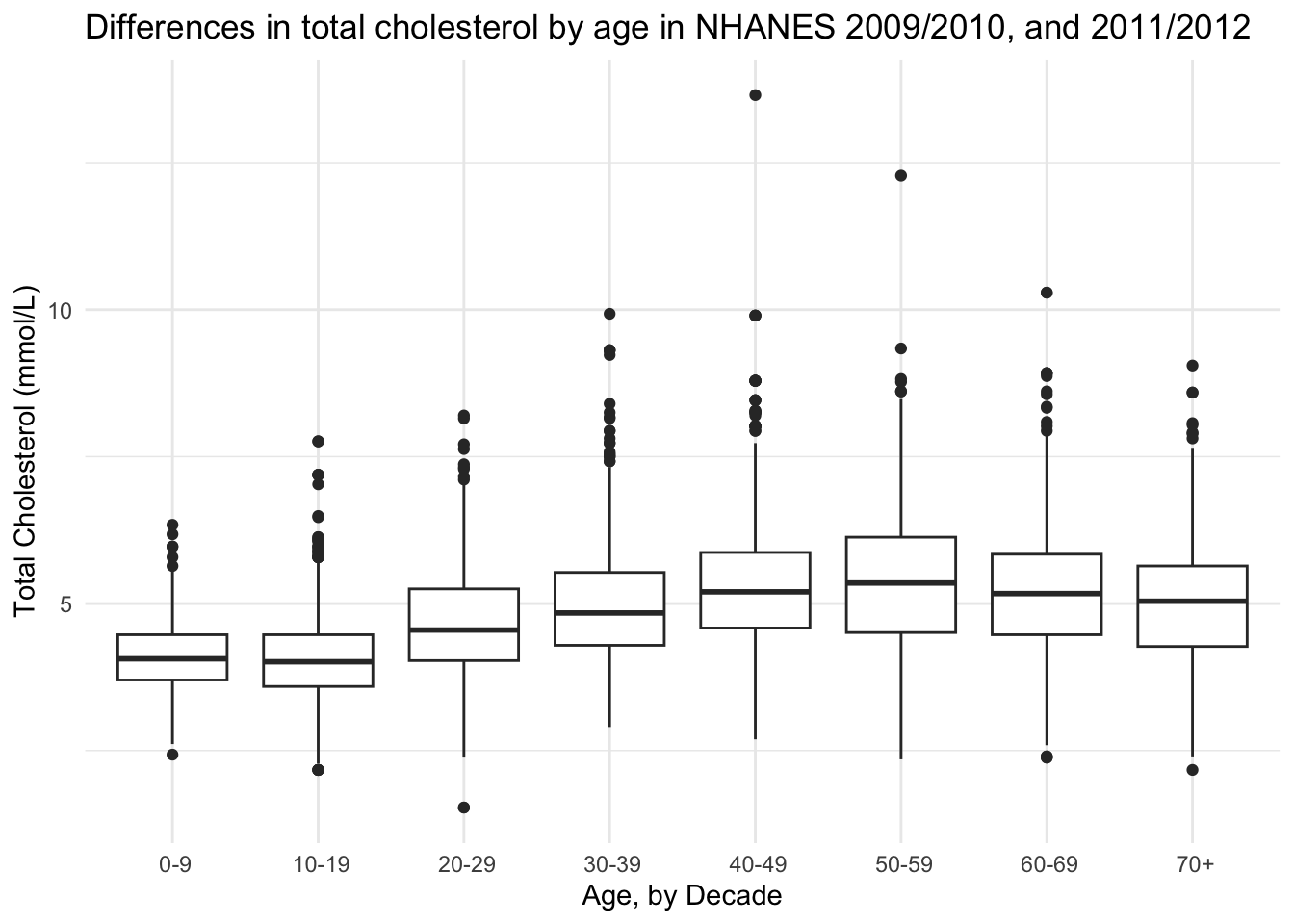
Would a violin plot be better?
NHANES %>%
drop_na(AgeDecade, TotChol) %>%
ggplot(aes(x = AgeDecade, y = TotChol, group = AgeDecade)) +
geom_violin() +
theme_minimal() +
theme(legend.position = "none") +
labs(x = "Age, by Decade",
y = "Total Cholesterol (mmol/L)",
title = "Differences in total cholesterol by age in NHANES 2009/2010, and 2011/2012")
Eh I think I like the boxplot better.
Use stat_compare_means()
NHANES %>%
drop_na(AgeDecade, TotChol) %>%
ggplot(aes(x = AgeDecade, y = TotChol, group = AgeDecade)) +
geom_boxplot() +
stat_compare_means() +
theme_minimal() +
theme(legend.position = "none") +
labs(x = "Age, by Decade",
y = "Total Cholesterol (mmol/L)",
title = "Differences in total cholesterol by age from NHANES 2009/2010, and 2011/2012")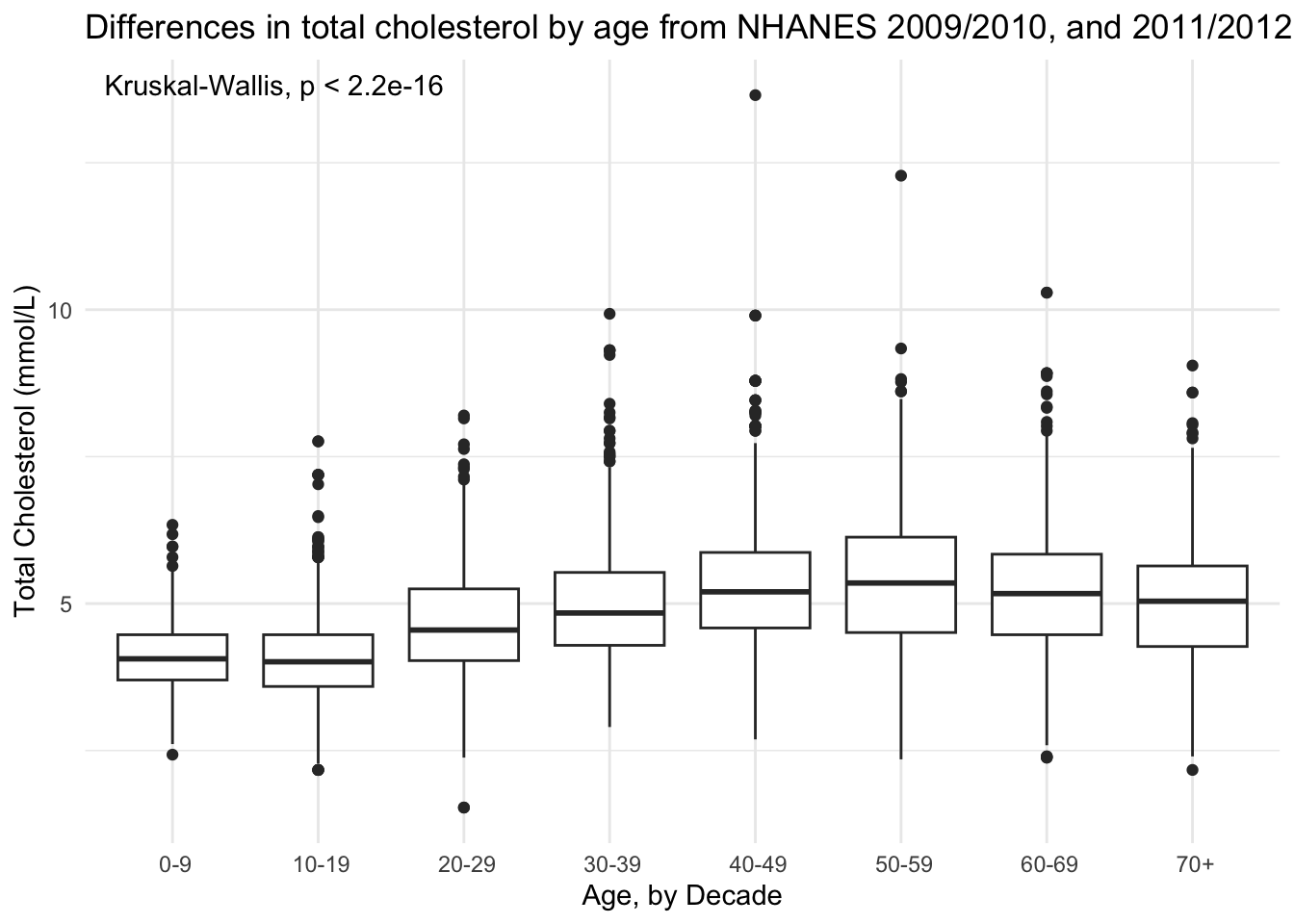
Testing assumptions
Normality
# testing normality by group
NHANES %>%
drop_na(AgeDecade, TotChol) %>% # remove NAs
group_by(AgeDecade) %>%
shapiro_test(TotChol) # test for normality# A tibble: 8 × 4
AgeDecade variable statistic p
<fct> <chr> <dbl> <dbl>
1 " 0-9" TotChol 0.986 5.23e- 4
2 " 10-19" TotChol 0.971 5.15e-15
3 " 20-29" TotChol 0.988 1.85e- 8
4 " 30-39" TotChol 0.963 1.58e-17
5 " 40-49" TotChol 0.960 7.88e-19
6 " 50-59" TotChol 0.987 6.76e- 9
7 " 60-69" TotChol 0.986 2.11e- 7
8 " 70+" TotChol 0.983 6.20e- 6Not normal.
Constant variance
NHANES %>%
drop_na(AgeDecade, TotChol) %>% # remove NAs
levene_test(TotChol ~ AgeDecade) # test for constant variance# A tibble: 1 × 4
df1 df2 statistic p
<int> <int> <dbl> <dbl>
1 7 8158 48.6 4.39e-68Non constant variance. Non-parametric it is.
Log transformed tests
NHANES_log <- NHANES %>%
mutate(TotChol_log2 = log2(TotChol))Normality
# testing normality by group
NHANES_log %>%
drop_na(AgeDecade, TotChol_log2) %>% # remove NAs
group_by(AgeDecade) %>%
shapiro_test(TotChol_log2) # test for normality# A tibble: 8 × 4
AgeDecade variable statistic p
<fct> <chr> <dbl> <dbl>
1 " 0-9" TotChol_log2 0.995 0.219
2 " 10-19" TotChol_log2 0.991 0.00000180
3 " 20-29" TotChol_log2 0.989 0.0000000306
4 " 30-39" TotChol_log2 0.995 0.000536
5 " 40-49" TotChol_log2 0.993 0.00000977
6 " 50-59" TotChol_log2 0.993 0.0000100
7 " 60-69" TotChol_log2 0.989 0.00000472
8 " 70+" TotChol_log2 0.995 0.0751 Still pretty not normal via Shapiro Test. Let’s look at the log2 transformed total choletserol distributions across the different age groups.
NHANES_log %>%
drop_na(TotChol_log2, AgeDecade) %>%
ggplot(aes(x = TotChol_log2)) +
geom_histogram() +
facet_wrap(vars(AgeDecade)) +
theme_classic() +
labs(x = "Log2 Total Cholesterol",
y = "Count",
title = "Distribution of cholesterol levels by age")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.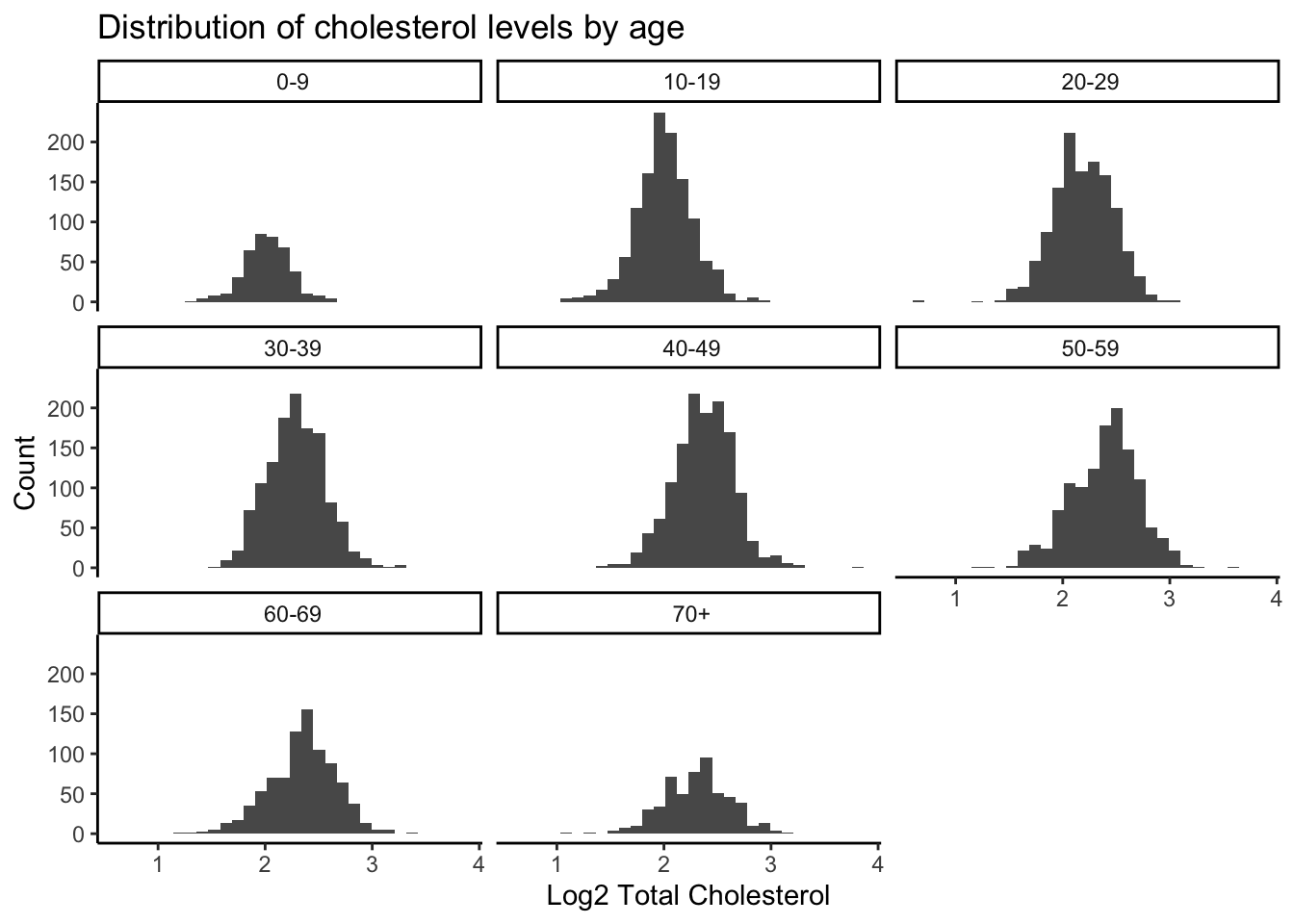
These actually look reasonably normal to me.
Constant variance
NHANES_log %>%
drop_na(AgeDecade, TotChol_log2) %>% # remove NAs
levene_test(TotChol_log2 ~ AgeDecade) # test for constant variance# A tibble: 1 × 4
df1 df2 statistic p
<int> <int> <dbl> <dbl>
1 7 8158 16.8 4.03e-22Still not constant variance.
Kruskal Wallis test
(kruskal_chol <- NHANES %>%
drop_na(AgeDecade, TotChol) %>% # remove NAs
kruskal_test(TotChol ~ AgeDecade))# A tibble: 1 × 6
.y. n statistic df p method
* <chr> <int> <dbl> <int> <dbl> <chr>
1 TotChol 8166 1672. 7 0 Kruskal-WallisOk significant difference exists. Where is it?
Post-hoc analysis
Run Dunn test
(kruskal_chol_posthoc <- NHANES %>%
drop_na(AgeDecade, TotChol) %>% # remove NAs
dunn_test(TotChol ~ AgeDecade,
p.adjust.method = "BH")) # Benjamini Hochberg multiple testing correction# A tibble: 28 × 9
.y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
1 TotChol " 0-9" " 10-… 415 1214 0.0500 9.60e- 1 9.60e- 1 ns
2 TotChol " 0-9" " 20-… 415 1257 10.6 3.66e- 26 6.83e- 26 ****
3 TotChol " 0-9" " 30-… 415 1273 15.9 1.02e- 56 2.86e- 56 ****
4 TotChol " 0-9" " 40-… 415 1354 21.3 2.60e-100 1.22e- 99 ****
5 TotChol " 0-9" " 50-… 415 1234 22.2 8.53e-109 4.78e-108 ****
6 TotChol " 0-9" " 60-… 415 873 18.8 1.16e- 78 4.64e- 78 ****
7 TotChol " 0-9" " 70+" 415 546 14.9 4.59e- 50 1.07e- 49 ****
8 TotChol " 10-1… " 20-… 1214 1257 14.8 1.16e- 49 2.50e- 49 ****
9 TotChol " 10-1… " 30-… 1214 1273 22.3 4.50e-110 3.15e-109 ****
10 TotChol " 10-1… " 40-… 1214 1354 30.1 3.66e-199 5.13e-198 ****
# ℹ 18 more rowsUse rcompanion::cldList() to create the groups for us. Reading the documentation about cldList() helped me learn that:
- there needs to be a formula that compares the p-values (here, p.adj) to a comparison column (here, one I created called comparison)
- there needs to be a comparison column that is in the form similar to “Treat.A - Treat.B = 0” where
=,0are removed by default. The removal of0affects our group names but we can fix that later. Since we have hyphens in our group names, I removed them since this column only allows one hyphen between the groups to be compared - set a threshold for what p-value is considered significant
To do this, first:
- I removed the hyphen from group1 and group2 in new variables called group1_rep and group2_rep
- Then, I made a new column called comparison that combined the values from group1_rep and group2_rep
# combine group1 and group2 to make one column called comparison
# then replace hyphens with something else because cldList can only have one hyphen
kruskal_chol_posthoc_1 <- kruskal_chol_posthoc %>%
mutate(group1_rep = str_replace_all(group1, pattern = "-", replacement = "to"),
group2_rep = str_replace_all(group2, pattern = "-", replacement = "to")) %>%
mutate(comparison = glue("{group1_rep} -{group2_rep}"))
knitr::kable(head(kruskal_chol_posthoc_1))| .y. | group1 | group2 | n1 | n2 | statistic | p | p.adj | p.adj.signif | group1_rep | group2_rep | comparison |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TotChol | 0-9 | 10-19 | 415 | 1214 | 0.0499933 | 0.9601277 | 0.9601277 | ns | 0to9 | 10to19 | 0to9 - 10to19 |
| TotChol | 0-9 | 20-29 | 415 | 1257 | 10.5808362 | 0.0000000 | 0.0000000 | **** | 0to9 | 20to29 | 0to9 - 20to29 |
| TotChol | 0-9 | 30-39 | 415 | 1273 | 15.8700258 | 0.0000000 | 0.0000000 | **** | 0to9 | 30to39 | 0to9 - 30to39 |
| TotChol | 0-9 | 40-49 | 415 | 1354 | 21.2610617 | 0.0000000 | 0.0000000 | **** | 0to9 | 40to49 | 0to9 - 40to49 |
| TotChol | 0-9 | 50-59 | 415 | 1234 | 22.1590557 | 0.0000000 | 0.0000000 | **** | 0to9 | 50to59 | 0to9 - 50to59 |
| TotChol | 0-9 | 60-69 | 415 | 873 | 18.7771929 | 0.0000000 | 0.0000000 | **** | 0to9 | 60to69 | 0to9 - 60to69 |
# run cldList()
(group_cldList <- cldList(p.adj ~ comparison,
data = kruskal_chol_posthoc_1,
threshold = 0.05)) Group Letter MonoLetter
1 to9 a a
2 1to19 a a
3 2to29 b b
4 3to39 c c
5 4to49 de de
6 5to59 d d
7 6to69 e e
8 7+ c c Or, you could create groups from kruskal_chol_posthoc results manually.
unique(NHANES$AgeDecade)[1] 30-39 0-9 40-49 60-69 50-59 10-19 20-29 70+ <NA>
Levels: 0-9 10-19 20-29 30-39 40-49 50-59 60-69 70+(group_manual <-
data.frame(group = levels(NHANES$AgeDecade), # use levels to get the right order
letter = c("a", "a", "b", "c", "de", "d", "e", "c"))) # letters manually group letter
1 0-9 a
2 10-19 a
3 20-29 b
4 30-39 c
5 40-49 de
6 50-59 d
7 60-69 e
8 70+ cMake a dataframe that has the maximum total cholesterol for each age so that we know where to place the numbers on the plot. I was having some trouble with the summarize() function from dplyr being masked by one from Hmisc so I’m referring to the one I want explicitly.
(max_chol <- NHANES %>%
drop_na(TotChol, AgeDecade) %>%
group_by(AgeDecade) %>%
dplyr::summarize(max_tot_chol = max(TotChol)))# A tibble: 8 × 2
AgeDecade max_tot_chol
<fct> <dbl>
1 " 0-9" 6.34
2 " 10-19" 7.76
3 " 20-29" 8.2
4 " 30-39" 9.93
5 " 40-49" 13.6
6 " 50-59" 12.3
7 " 60-69" 10.3
8 " 70+" 9.05Bind the groups to the maximum cholesterol df.
(dunn_for_plotting <- bind_cols(max_chol, group_cldList$Letter) %>%
rename(Letter = 3)) # rename the third column "Letter"New names:
• `` -> `...3`# A tibble: 8 × 3
AgeDecade max_tot_chol Letter
<fct> <dbl> <chr>
1 " 0-9" 6.34 a
2 " 10-19" 7.76 a
3 " 20-29" 8.2 b
4 " 30-39" 9.93 c
5 " 40-49" 13.6 de
6 " 50-59" 12.3 d
7 " 60-69" 10.3 e
8 " 70+" 9.05 c Plot
# using geom_text()
totchol_age_baseplot +
geom_text(data = dunn_for_plotting,
aes(x = AgeDecade,
y = max_tot_chol + 1,
label = Letter)) +
labs(caption = "Groups with different letters are significant different using the Kruskal Wallis test, \nand the Dunn test for pairwise comparisons at p < 0.05")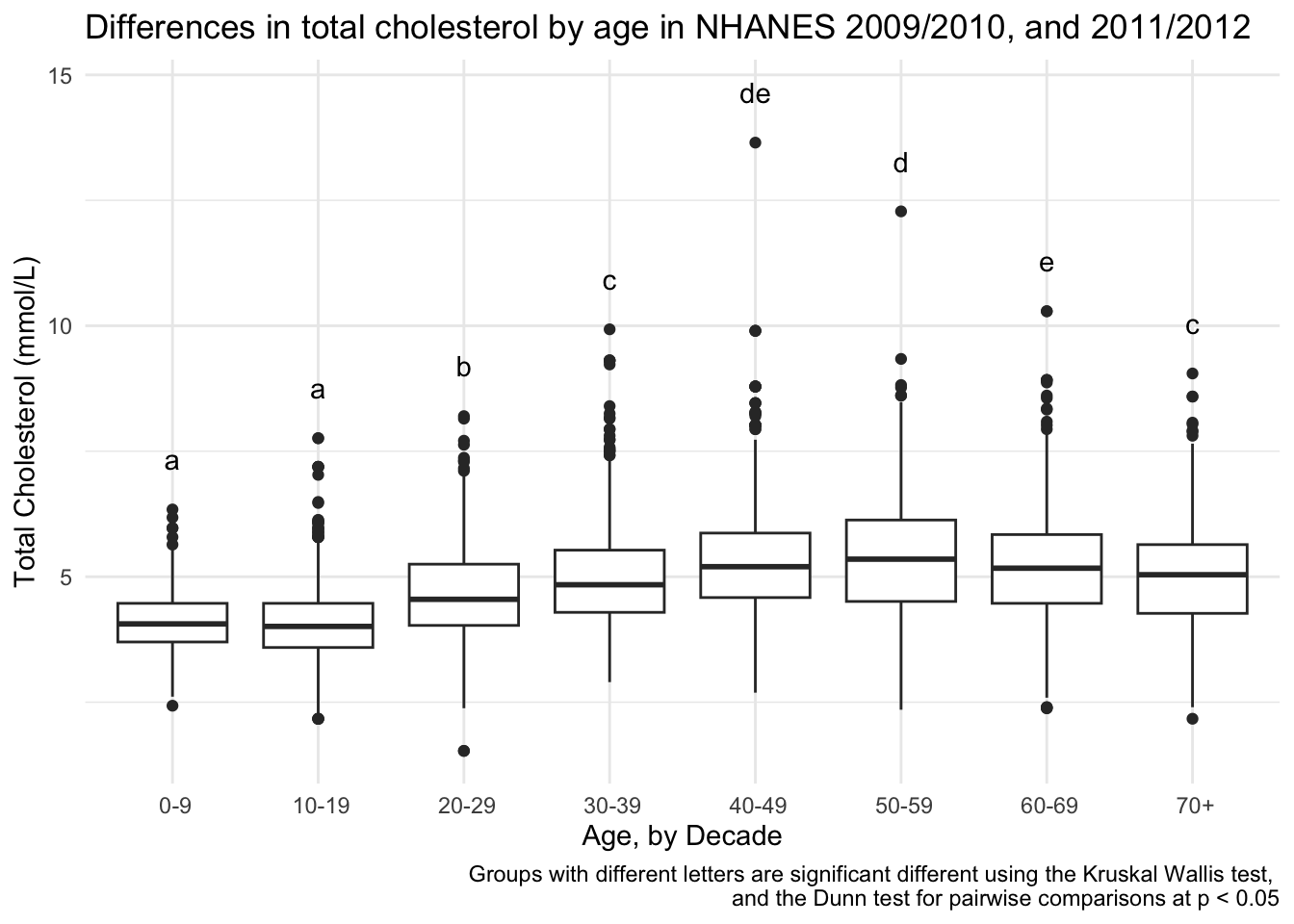
# using annotate()
totchol_age_baseplot +
annotate(geom = "text",
x = seq(1:8),
y = dunn_for_plotting$max_tot_chol + 1,
label = dunn_for_plotting$Letter) +
labs(caption = "Groups with different letters are significant different using the Kruskal Wallis test, \nand the Dunn test for pairwise comparisons at p < 0.05")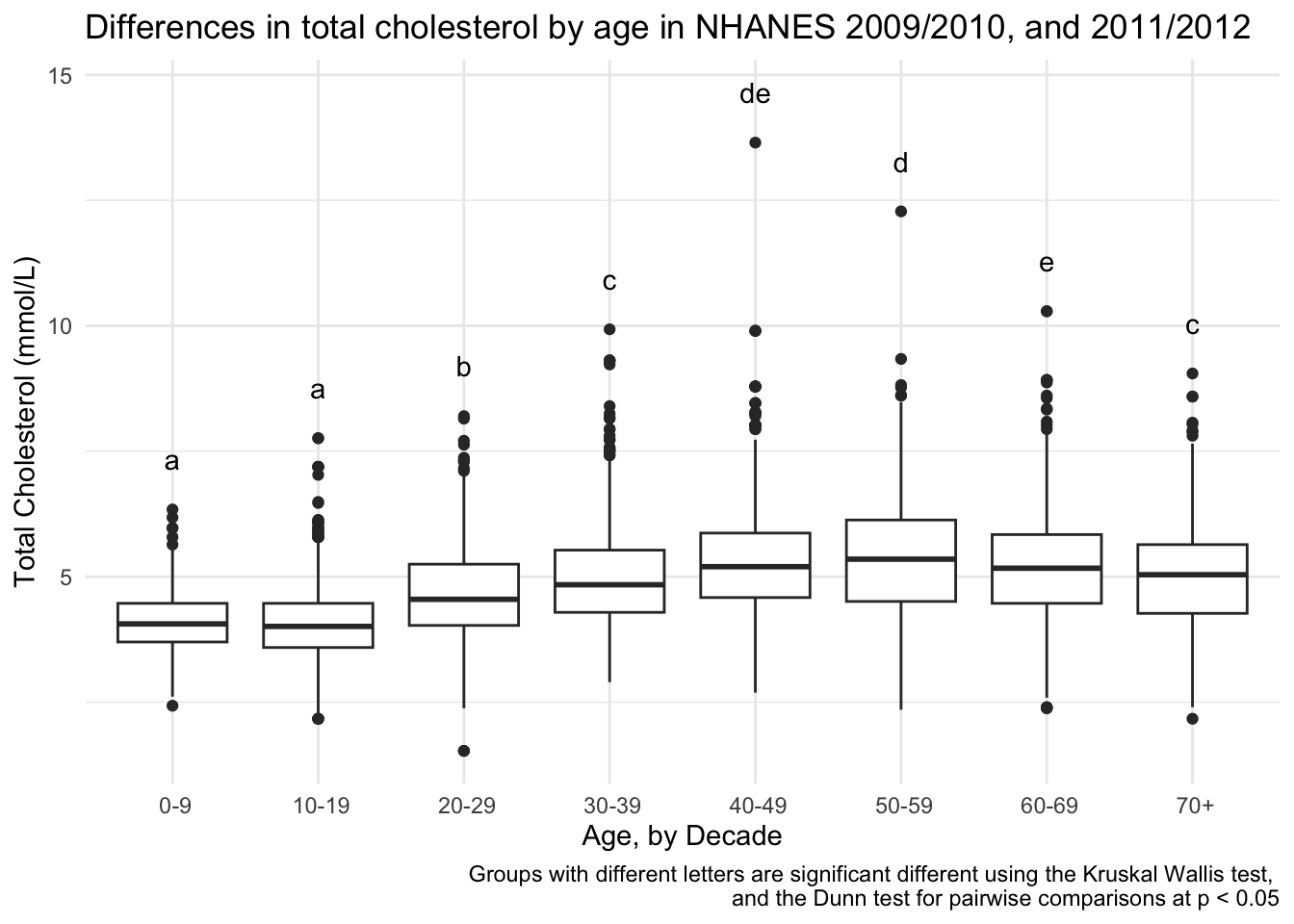
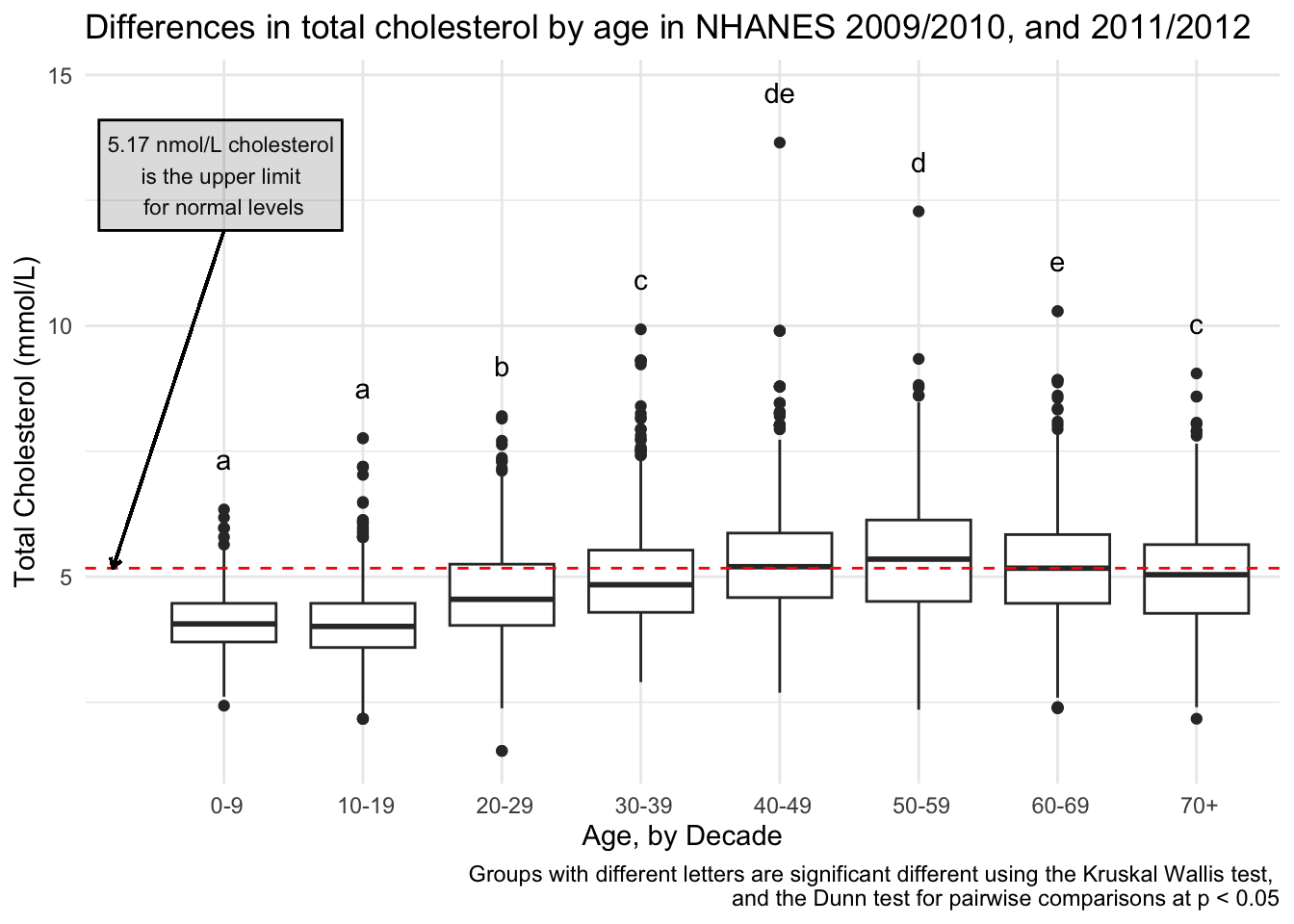
I also decided to add for context, what the cut-off for normal cholesterol is, so someone can see how these values relate to normal values. A normal cholesterol level is below 200 mg/dL or below 5.17 mmol/L.
totchol_age_baseplot +
expand_limits(x = 0) + # a little more space to add a note
geom_hline(yintercept = 5.17, # set the yintercept
linetype = "dashed", # make the line dashed
color = "red") + # make the linered
# add means comparison letters
annotate(geom = "text",
x = seq(1:8),
y = dunn_for_plotting$max_tot_chol + 1,
label = dunn_for_plotting$Letter) +
# add a lil note about cholesterol
annotate(geom = "text",
x = 1,
y = 13,
size = 3,
label = "5.17 nmol/L cholesterol \nis the upper limit \nfor normal levels") +
# put that note in a box
annotate(geom = "rect",
xmin = 0.1,
xmax = 1.85,
ymin = 11.9,
ymax = 14.1,
color = "black",
alpha = .2) + # transparency
# add an arrow from the note to the horizontal line
geom_segment(aes(x = 1, y = 11.9, xend = 0.2, yend = 5.17),
arrow = arrow(length = unit(0.15, "cm"))) +
labs(caption = "Groups with different letters are significant different using the Kruskal Wallis test, \nand the Dunn test for pairwise comparisons at p < 0.05")